Introduction
Version 12 of Azure SQL Database has now reached General Availability in Europe. See the announcement here. So, now it is time to re-run those earlier performance tests, to see where performance has settled at.
This post includes:
- updated read / write metrics
- a new CPU benchmark and
- updated memory allocation metrics.
Microsoft publish very few absolute performance metrics regarding Azure SQL Database. The tests described here involve indirectly calculating absolute metrics. Methodologies are described below.
All tests were conducted at least three times to check for consistency and to reduce the risk of any random variations affecting the results. (That is a lot of tests, data collection and processing – nearly 80 test runs in total).
For reference, these tests were conducted in the Western Europe data centre, against the following Azure SQL Database version (select @@version):
- Microsoft SQL Azure (RTM) – 12.0.2000.8 Jan 29 2015 07:51:58
Unit of Measure
Note that the unit of measure for throughput rates in this post (and the other posts in this series) are MB per minute. This is primarily because, at the lower tiers (and even the higher tiers until recently), rates of MB per second would be 0.xx, 1.xx, etc. As the throughput rates have been increased, particularly recently, this has led to the higher performance level rates entering the thousands, so we have the opposite problem (i.e. too large numbers at the top end). Still, despite that, I have opted to retain the same unit of measure throughout, to keep comparisons easier. In the future, I may move to MB per second, if I get a lot of feedback in that direction.
Read Rate Tests
The test is based around reading data from a series of identical tables. The tables contain a mixture of basic data types – no large object data types, all in-row data. Average row size is around 410 bytes.
The test involved using a set of test data that is likely much larger than the SQL Buffer Pool sizes:
- Basic: 1.9 GB
- Standard S0: 10 GB
- Standard S1: 20 GB
- Standard S2: 30 GB
- Standard S3: 36 GB
- Premium P1 and P2: 36 GB
A new database was created in each service level and populated to the sizes given above. The database was then copied (using the Database Copy facility). My understanding is that this performs a physical copy of the database files (determined from some other tests I have undertaken previously) and results in a new database which has an empty buffer pool i.e. no data cached in memory. The test then involves sequentially reading through the database reading data from disk allowing the maximum physical disk read rate to be measured.
Data was divided into 1 GB tables (100 MB tables for Basic Tier) and each table was read sequentially.
The SQL statements used to read through the database were similar to the following:
select count(*) from Table0
where [Bit1] is not null and
[TinyInt1] between 10 and 240 and
[Int3] between 100000 and 2000000000 and
[Money2] between 0 and 10000000
No indexes (other than a clustered index on the RowId primary key) were present on the tables. A count(*) was used to ensure performance is not held back either by complex processing or by waiting for slow network I/O returning results to the client.
Results

The blue bars show performance values obtained in my first tests in July 2014 during the preview of the newer service tiers (Basic, Standard and Premium). The red bars show performance in the current generally available version (i.e. V11) of SQL Database. V12 preview performance, measured in December 2014, is shown in the green bars. The orange bars show V12 GA performance (except for Web/Business, which only exists at v11 – the orange Web/Business bar shows the result of a v11 test conducted in January 2015).
Premium P1 and P2 were also tested:

Several interesting observations here. Most notably, Premium P1 and P2 have received very significant read performance increases. Premium performance now makes Web/Business performance appear tiny in comparison. With this performance we can perhaps now understand why Microsoft set the Premium Tier prices so expensively in comparison to Web/Business. No doubt, last summer when the Premium Tier pricing was announced, it was with this performance level in mind. I expect Microsoft faced an interesting dilemma last year, do they pitch the initial Premium tier price lower in July 2014 (in line with the initial lower performance) and then dramatically increase it in January 2015 as this v12 upgrade comes on-line (and annoy customers in Jan 2015), or do they set it higher from the start (at the risk of making Premium look very poor value initially). Obviously they chose the latter, and now the full story is becoming clearer.
This is a good point to note that at the beginning of these tests, the SQL Server Buffer Pool was empty (verified by checking the memory usage column in the sys.dm_db_resource_states DMV). In addition, five to six hours had also elapsed between the creation of the database copies and the running of the tests, which should reduce potential effects from storage layer caching (though there is no way to verify this). Thus the tests should be measuring the read rate from disk, not cache.
Standard Tier v12 GA performance for S1, S2 and S3 is significantly less than in preview. However, it would not be fair to criticise Microsoft for any performance changes here. It was quite clearly stated during the preview that performance could/would be adjusted as the service heads towards general availability.
More important is the comparison between current v11 performance and v12 GA performance. Here we can see that maximum read rates under S0 and S1 have more than doubled. S0 and S2 have received a slight increase. Curiously Basic tier seems to have received a slight decrease.
It is particularly interesting to see where S2 and S3 read performance now sits. S2 runs at almost the exact average of Web/Business. Current Web/Business read performance is on average around 550 MB per minute though is quite volatile flipping between 200 MB per minute and 800 MB per minute (see my previous post here for more details).
S3 runs at on average 900 MB per minute – i.e. well above the average Web/Business performance and above even the Web/Business peak rates.
There is a wide gap between S3 performance and P1 performance. Both S3 and P1 are rated at 100 DTUs, though P1 costs five times as much as S3. Clearly, for that price difference you get a massive amount of extra read-performance. This suggests that the DTU figures do not take into account I/O performance limits/variations between tiers / performance levels.
Read Rate Consistency
The following charts show how the read rates varied over the duration of the tests. Each read test was performance three times at each performance level – labelled as (a), (b) and (c) in the charts:

A point is plotted on the chart for each table read during the test. For Basic tier, each table contained 100 MB (showing first 1GB only on the chart). For the other service tiers, each table contained 1 GB.
The chart shows that read rates were generally very consistent throughout. Continuing with the other service tiers:

S1 read performance was generally consistent, S2 read performance varied a little but there does seem to be some quite wide variation of S3 read performance. For P1 and P2:

Again, both P1 and P2 are reasonably consistent in their performance. The P2a test run was a little more variable than the other two P2 tests. S3 is shown on this chart to illustrate just how much higher Premium performance is than S3. On this chart, the scale is such that the relatively wider variation in S3 performance (shown on the previous chart) is barely even visible here.
Read Test Resource Usage
During the read tests, the data from the sys.dm_db_resource_stats DMV was captured. This showed that, in the S0, S1 and S2 tests, around 90% of the available read IO resources were being consumed, so these results should be a good reflection of the maximum rates available.
The S3 result was a little more volatile, showing that at times significantly less than 100% of the available read resources were being consumed.

As you may expect, the drops in read utilisation are generally speaking at the same points in the test as the drops in read rate occur (e.g. for at 8 GB in S3b and 22 GB in S3c). This suggests the I/O subsystem was unable to supply the maximum amount of data per second that SQL Server could consume in this performance level. All in all this suggests that Microsoft still need to apply some performance optimisations for S3.
Interestingly, the chart for P2 also shows that it was not consuming all of the theoretically available read resources:

This chart has less detail than previous charts. This is because P2 read the test database very quickly, and there is only one row in the sys.dm_db_resource_stats DMV for every fifteen seconds. Even still, the general trend is still clear enough. The test query was consuming only around 70% of the available read resources during the test.
Knowing that the P2 test read on average at 19,500 MB per minute at 70% read utilisation, we can estimate that the theoretical P2 maximum read rate would be around 28 GB per minute. Similarly, we can estimate that the maximum theoretical read rate for P1 (which was reading 11,800 MB per minute on average at 80% read utilisation) would be around 15 GB per minute.
More Read Utilisation charts for the other performance levels can be found in an appendix at the end of this article.
Write Rate Tests
This test aimed to cache a relatively small amount of data in the buffer pool (100 MB), then repeatedly write this until a specified total data volume had been written. Each 100 MB chunk was written using a single Insert statement. The total data volume was specified to aim for a test very roughly around 30 minutes to 1 hour in length The time taken would then allow an estimate of the maximum write rate. Total data volumes used were:
- Basic and S0 – 1 GB.
- S1, S2 and S3 – 2 GB.
- P1 – 5 GB.
- P2 – 10 GB.
Results

Both Basic Tier and all four performance levels within Standard Tier have received notable write rate increases.
However the first question here is this: why is S3 write performance notably less than S2 write performance? Tests at both S2 and S3 were repeated three times each – the results were consistent in all cases. This seems very strange and I have put this question to Microsoft.
Edit: I have received a response from Microsoft that the current write rates for the Standard Tiers are in v12 are about to be adjusted. Once this has been completed I will update the details here.
It is interesting to note however, that none of the performance levels in Standard Tier come close to matching the Web/Business write performance. Having said that, if S3 write performance was actually above S2 (as surely it is supposed to be) than S3 may actually come close to Web/Business. I can see this being a key question for many existing Web/Business customers.
Moving on to write performance of the Premium Tier:

P1 and P2 see significant write performance increases – a factor of almost three over current v11. P1 write performance is now clearly higher than Web/Business – which is not the case in v11. v12 P1 writes also outperform v11 P2.
Write Rate Consistency
The following charts show how the write rates varied over the duration of the tests. Each write test was performance three times at each performance level – labelled as (a), (b) and (c) in the following charts.
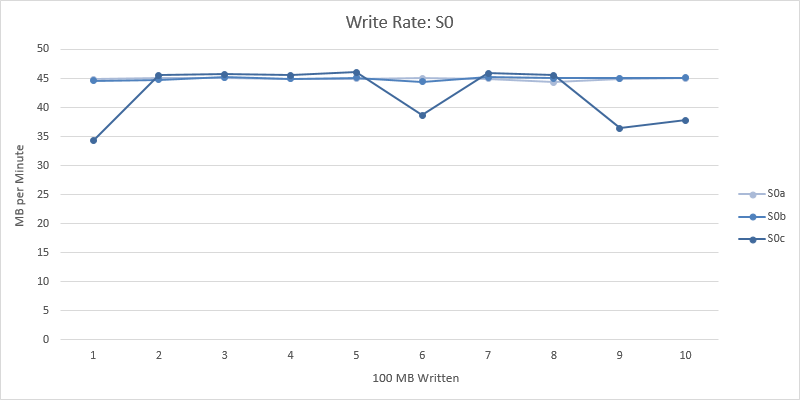
This data shows Basic, S0 and S1 writing very consistently at around 45 MB per minute throughout. These charts are included in an appendix at the end of this post (since they all write at around 45 MB per minute, each performance level must be plotted on separate charts to avoid all the lines overlapping – which results in just too many charts to include in the main body of the text).
Comparing S1, S2, S3 and P1:
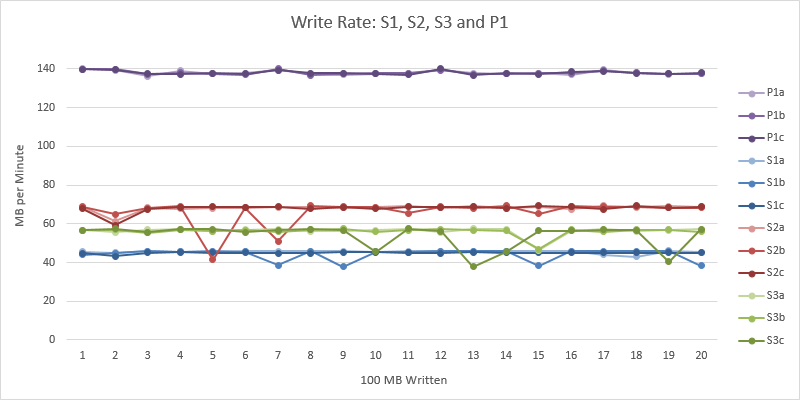
This chart shows how the write rates for S1, S2, S3 and P1 are very consistent in all tests.
This chart also shows how very consistently S2 outperforms S3. Surely there is a bug here in Azure?
Now comparing P1 and P2:

Again, the write rate is extremely consistent for P2.
Write Test Resource Usage
During the write tests, the data from the sys.dm_db_resource_stats DMV was captured. Unsurprisingly given the consistency shown above, this data shows the write-utilisation at very close to 100% (i.e. 98%, 99%), throughout. As such, there is very little point plotting the data.
CPU Tests
In previous series of tests I have not compared CPU performance between the different performance levels. As part of this series of tests, I decided running some tests to compare CPU performance between the different performance levels might be interesting.
The test is based around running the same CPU-heavy workload in each of the different performance levels and comparing the results. The chosen workload is a forced loop join where the join condition is something non-trivial, for these tests:
(abs(((t1.Int1 * t2.Int2) + t1.Int3) - ((t2.Int1 * t1.Int2) + t2.Int4)) < 17) and (abs((power(t1.Int5 % 5, 3) - (t2.Int5 % 25))) < 7)
This query means that a relatively small number of rows will require a significant amount of time to process. Using a relatively small number of rows is important because it eliminates any potential delays due to time waiting for the data to be read. The test table was created with 280,000 rows of data which is in total around 10 MB. This entire table was read before the test began properly to get the data loaded into the buffer pool. All in all this means close to all of the query execution time is CPU time.
The query was written so that SQL Server should use a parallelised execution plan. This allows the workload to expand to exploit the full amount of CPU resources available within the performance level. The exact same data was used for every test.
The test script used automatically ran the test multiple times, recording the results for each test. The number of rows selected from the test table was increased with each test (SELECT TOP … ORDER BY RowId was used to ensure data is picked up in the same way in each performance level). The number of rows was increased until the SELECT ran for over two minutes, at which time no further tests were peformed (i.e. the row count wasn’t increased further).
The test was developed on my development machine. This has the added advantage that the Azure results can be compared to a machine of known specification. My development machine was built in 2010 – at the time it was a relatively high end machine. At the core of the machine is an Intel i7 930 2.8 GHz quad core processor with hyperthreading (i.e. eight logical cores) running on an ASUS P6T Deluxe motherboard. Details of the processor can be found here. Details of the motherboard here. My development machine is running an up to date copy of SQL Server 2014 so it is assumed that the engine internals involved in the test are close enough to those running in Azure SQL Database to make a comparison valid.
Results
Given the relatively large number of test cases, each with different row counts, it is easier to display these results in tabular form:

The table above shows three metrics, explained below.
Average query time in seconds
This shows the time taken to execute the test query in each performance level – row count combination. For example, in the S0 column we can see that 34 seconds were required to perform the join, where the first 3000 rows were selected from the table. The Ref column refers to my development machine (i.e. the reference machine).
In case anyone is jumping to the wrong idea… as I said above, the test query used was deliberately chosen to take a relatively long time to execute. This query time is not indicative of the time taken to join 3000 rows in a typical business scenario! In fact, the actual execution time is not really meaningful since the query is junk – all we care about is that it is a relatively CPU heavy workload that we can repeatedly execute in different environments and compare the execution times.
It is by comparing results between different environments that more meaningful insights can be gained.
When interpreting this table, it is important to understand what are valid/simple comparisons and what aren’t. Comparing along the rows is valid e.g. comparing the the time to join 7500 rows on an S0 and an S1. Joining the first 7500 rows from the test table on an S2 required 49 seconds. Performing exactly the same join across the same test data on an S3 required 24 seconds. Since it was the same workload, we can say S3 is twice as powerful in CPU terms as S2.
Comparing between rows in this table is not so simple. I.e. this workload does not scale linearly. E.g. on an S2, joining 5000 rows required 22 seconds. Joining 10000 rows required 86 seconds. As we are talking about a loop join here, double the rows equals four times the workload, which the results roughly agree with.
Finally, very short query times are unlikely to be good sources of information. It is possible in much shorter queries that SQL Server may use a different execution plan. It is also possible a larger percentage of the time may be attributable to non-CPU sources. This is roughly those results from joining 2000 rows or less, which is why these rows have been grayed out in the table.
Performance Multiple of Reference System (Quad Core 2.8 GHz i7 930)
This metric is shown in the middle part of the table. If we assign my development machine a metric value of 1, then comparing the query times between this system and the different Azure performance levels, we can see what fraction of my development machine CPU resources those performance levels offer. For example, if a (CPU-heavy) query runs in ten seconds on my machine and takes twenty seconds in a particular performance level in Azure, we can say that this performance level in Azure offers half the CPU resources of my development machine.
The numbers highlighted in yellow show these results. These show that, for example, S3 offers about one-fifth of the CPU resources of my dedicated development machine.
DTU Multiple
This metric is shown in the latter part of the table. Taking S2 at 50 DTUs as a reference point and using the performance multiples above, it is possible to calculate the effective DTUs of each of the other performance levels. The numbers highlighted in green show these results.
Discussion
It is interesting just how closely these results align with the number of DTUs allocated per performance level in Azure. It is clear that the CPU resources allocated to each performance level in Azure SQL Database very closely reflect the DTU values stated by Microsoft.
By this calculation, my desktop machine offers the equivalent (in terms of CPU resources) of 500 DTUs! I was a little surprised that even a P2 database has less than half of the CPU resources of my development machine. Though, as I said, my development machine is still moderately high-spec (and probably way overpowered in CPU terms) and of course, my development machine does not offer any of the other great features in Azure SQL DB!
P2 Query Plans
In some of the test results, P2 appears to only offer around 150 DTUs. These are the cells highlighted in red above. This was actually due to Azure SQL DB using a slower query plan when executing these test cases. For all of the other tests, the sys.dm_db_resource_stats DMV showed 100% CPU utilisation when running the tests. For the test cases highlighted in red, CPU utilisation was reported at being only around 70%, hence the query took longer to execute. From the 17500 row test case onwards, the faster query plan was used. The changeover between the two plans can be seen clearly in the CPU Time results. Normally, in a given performance level, as the row count is increased there is a significant CPU time increase too. However, while 15000 rows required 64 seconds to execute, 17500 rows required 66 seconds, i.e. only two seconds more, as a result of the switch to the faster query plan. These are the two timings highlighted in orange in the table above.
Memory Tests
The maximum possible memory usage under each of the performance levels can be estimated using the method described in my earlier post. This method was used again to obtain estimates for V12:
Results

These results show some significant changes to the memory allocated to each performance level between v11 and v12. S1 and S2 are able to access a significantly higher amount of memory in v12.
Interestingly S3 and P1 are allocated the same amount of memory, which mirrors the fact they both have the same DTU rating of 100. This does mean a significant reduction in the amount of memory available under P1, however this change does make some sense.
Under v11, the memory allocated was solely determined by service tier (i.e. Basic, Standard or Premium). All databases within a given tier had the same memory allocated, irrespective of the performance level. Under v12, this has become more fine grained, being based on both service tier and performance level within the tier. With this in mind, the change to P1 memory allocation can be seen to be more like a correction. Under v11, P1 was over allocated relative to P2 (or, from the other point of view, P2 was under-allocated compared to P1). The same applies to S0, S1, S2 and now S3.
Conclusion
Version 12 of Azure SQL Database has brought many significant performance increases over current v11. The read rate improvements for S1 and S2 are significant. The read rate improvements for P1 and P2 are dramatic. The write rate improvements are also significant, especially again for the Premium Tier. Finally this lifts P1 performance well above that of Web/Business.
The most significant questions raised by these tests are around S3. S3 write performance is less than S2 – surely a bug/issue. There also appears to be some volatility around the S3 read rate consistency currently, hopefully this will settle down shortly.
For customers looking to migrate from Web/Business, S3 still looks promising, however the question of the S3 write rate needs answering. If this is not rectified, then moving from Web/Business to S3 will incur a roughly 50% cut in the write rate available. If affordable, Premium now offers a level of resources significantly / dramatically above that available in Web/Business.
These tests have shown how the DTUs allocated to each performance level now closely reflect the resources available in each tier. For the memory and CPU allocation there is close to a direct correlation.
Edit: 2nd Feb 2015: Additional Test Results
I have run a couple of additional tests (following the same methodology) since the rest of this post was written that have thrown up some interesting results. I’ll walk through them:
Massive P2 Read Rates
I conducted a further short series of P2 read tests that have shown dramatically different read rates. I repeated the tests in the other tiers which did not show any significant increase.
- Repeat of P2 Read Test: Average Read Rate = 39,200 MB per minute
- Repeat of P2 Read Test: Average Read Rate = 39,800 MB per minute
Clearly a massive increase on the earlier tests. The read rates were sustained throughout the tests. Several hours elapsed between the database copies being created and the tests being run (as in the earlier tests). Buffer pool was empty at the start of the tests. Perhaps the effect of data in a storage cache? - Repeat of P1 Read Test: Average Read Rate = 12,000 MB per minute
i.e. matches the earlier tests described in the main body of the post. - Repeat of S2 Read Test: Average Read Rate = 580 MB per minute
i.e. matches the earlier tests described in the main body of the post. - Repeat of S0 Read Test: Average Read Rate = 292 MB per minute
i.e. matches the earlier tests described in the main body of the post.
Effect of NOLOCK Hint
Using the NOLOCK hint (where practical) can increase the read rate, significantly so for the premium tier:
- P2 Read Test: Average Read Rate = 69,000 MB per minute
- P2 Read Test: Average Read Rate = 60,900 MB per minute
Almost double the P2 read rate result from earlier in the same day. - P1 Read Test: Average Read Rate = 13,800 MB per minute
i.e. around 2,000 MB per minute above the earlier result. - Average Read Rate = 750 MB per minute
i.e. around a 170 MB per minute increase over the earlier result. - Repeat of S0 Read Test: Average Read Rate = 340 MB per minute
i.e. around a 50 MB per minute over the earlier result.
Appendix: Additional Read Test Resource Usage Charts
See text above for explanation.

The Basic and S1 charts were very similar to the S0 chart, i.e. close to 100% read utilisation throughout (sorry, just too many charts to produce to create and include them all!).


Appendix: Additional Write Rate Consistency Charts
See text above for explanation.



Regarding the tests “inside SQL Server” (the count(*)): When the pages to be read are not physically contiguous and sequential there can be a severe performance hit. Did you check that the table was not fragmented? I’d check the avg_fragment_size_in_pages value from dm_db_index_physical_stats, not the fragmentation percentage (nobody seems to know what this is a percentage *of*). The value should be like 100 or more (that would correspond to on avg. 800KB chunks).
At the moment you seem to use hughe 100MB+ blobs. I’m kind of concerned they might be fragmented.
Consider using WITH (NOLOCK). That results in an allocation-order scan. This can help tremendously if the pages are contiguous but not sequential. This partly eliminates fragmentation from the test. But I doubt this will work for blobs.
“Each table was 1 GB in size.”: Note, that even when you freshly rebuild a table it can still end of highly non-contiguous. SQL Server has no fragmentation avoidance in its space allocation algorithms whatsoever. Often multiple tables end up perfectly interleaved.
I’d use one table with a clustered index (just because a heap is not allowed in all editions): (ID INT NOT NULL IDENTITY PRIMARY KEY, Padding char(7900) NOT NULL DEFAULT (”)). That way you have almost zero CPU usage. Even inserting data this way maxes out the disk. One row per page with trivial serialization costs.
Just trying to make sure you are aware of these concerns. I’m very interested in your work and in the validity of these tests.
The CPU numbers are really amazing. Very round numbers. Also, the relatively even ratio of your machine to theirs (.1, .2, .4) caught my attention. Must be coincidence.
By blobs, I assume you are referring to the SQL large object data types. None of the large object data types were used in any of the tests. The read and write test tables all had the same structure – a mixture of common data types: An incrementing row id, 4x bit, 2x tinyint, 2x smallint, 5x int, 4x datetime, 2x float, 3x money, char(2), char(10), varchar(40), varchar(100) and varchar(250). The varchar fields were populated with random values. Average row size was around 420 bytes (the varchar fields were not fully populated to their maximum length in every row).
You raise an interesting point about fragmentation. The test database was uploaded into Azure using the standard BACPAC Database Import process, which can leave some fragmentation. When I first ran these tests (last year), I ran a couple of comparison tests. One where the tables were rebuilt prior to the test and one where they weren’t. There was no difference in the test results. However, since then, premium read performance has risen significantly, so it might perhaps make a difference now. So yes, interesting point. And I wasn’t aware of the effect of the nolock hint, so thanks for that, I may well investigate that.
Looking at the resource utilisation data from the sys.dm_db_resource_stats DMV, the tests were reading at 90% ish read utilisation for most of the read tests (i.e. there was no possible way to read significantly faster). S3 showed some variability. In the premium tier were we a significant distance from hitting 100% read utilisation (P2 around 70% read utilisation, P1 around 80%). Knowing the rates we measured and that these equate to 70% (P1) and 80% (P2) read utilisation, we can actually estimate what the theoretical maximums for those tiers would be, i.e. P1 would be 15 GB per minute and P2 around 28 GB per minute. Whether fragmentation was involved or not here would require some more tests.
Interesting idea about the 1 row per page as a diagnostic test, though I am not sure if it is perhaps a little too synthetic/artificial to be a useful benchmark. If I have time, I may run a couple of quick tests using this for comparison.
Another way to look at my tests is that I haven’t done anything particularly special with the data, so these results should be easily achievable by others.
Re: CPU test results… I was pleased to see just how well that turned out (i.e. as you said, just how well the numbers matched/scaled against each other and corresponded to the number of DTUs). And yes, I also raised an eyebrow when I saw what exact fractions of my machine the Azure results turned out to be. I can’t really see how it could be anything other than a coincidence though.
Finally, thanks for the thoughts and taking the time to feedback. Thoughtful feedback is always appreciated.
Would it be possible to make your data generation and test scripts available? Being able to reproduce your test turns it from a test into a benchmark. Benchmarks are accessible to anyone and can be verified by third parties.
This is why I typically use something like TPC-C or TPC-H for testing different aspects of an RDBMS – they’re easily reproduced and I can share the settings I used to get my results. Without this information, I can’t verify your results and effectively form an opinion.
I’m being picky about this because, much like Microsoft’s DTUs, if I can’t verify something I can’t trust the numbers. This is why peer review is so important. Even if nobody goes through the trouble, we can still look at the methodology and decide for ourselves.
Also: please use an industry standard UOM. MB/minute looks shady.
Hi Jeremiah.
I’m happy to share the scripts and more detail about the methodology. I’m certainly not trying to hide it! Quite a bit of it is already in the various posts on this blog, though it is quite scattered given the number of posts on this topic. Striking a balance between results and methodology detail isn’t easy for these tests – frankly, the posts are long enough as it is! Also, I tend to only explain a test in detail the first time I run it, not every subsequent time. I try and link back. Also, until now, you are the first person that has asked for more detail 🙂
I have added some additional methodology information here:
https://cbailiss.wordpress.com/azure-sql-db-performance-tests/
(This is linked in the header of the blog for future reference).
Re: the TPC benchmarks… I am only familiar with those in passing. The idea for these tests came up when I first read Microsoft’s announcement of the Basic/Standard/Premium service tiers and could not get any kind of feel for the resources available in each performance level. So, I started simply and decided to try and get a handle on basic metrics like maximum read and write rates, etc. I shared those on the blog and here we are. I make no claims that these are the best or most insightful tests. If other people want to re-run them, improve them, etc that’s great!
Re: unit of measure, I outlined my reasons at the top of this post, thanks for the feedback on the point. I will take it and any other feedback on the topic on board for future posts.
Great work again Chris. A BIG THANK YOU for your efforts in giving us some clarity on the true performances behind SQL Azure database!
If you ever visit Japan, get in touch and I sure owe you a couple of beers!
Thanks Thierry. Glad the posts been helpful. I know you’ve followed the blog and the development of the newer service tiers since July last year – hopefully Microsoft are getting performance to where you need it to be now.
Regarding creating a realistic workload: I think it is more important to measure the resources provided in isolation. That way we can make predictions for *any* workload, not just a specific load deemed as realistic.
That’s why the Microsoft DTU value does not mean anything in absolute terms. If my app is just a bit over the buffer pool memory allotted then my app might have horrible performance. If it is just a little under I might see very high throughput. By this example you see that knowing the buffer pool size is the important insight. I can use it to predict my app’s performance. I couldn’t use *any* synthetic workload to make that prediction. I also couldn’t make that prediction from the CPU numbers. I must know the buffer pool size. This point generalizes to the other resources (disk, CPU).
I recommend testing resources in isolation.
The way you tested CPU is very much in this spirit. I think the test was pretty much ideal. No other resource except CPU was stressed. And indeed the results are very meaningful.
Regarding table structure: Try this experiment on your laptop: Insert many rows with the following script:
USE tempdb
CREATE TABLE T (ID INT NOT NULL PRIMARY KEY IDENTITY, SomeData INT)
INSERT INTO T (SomeData)
SELECT NULL
FROM sys.all_objects o1
CROSS JOIN sys.all_objects o2
CROSS JOIN sys.all_objects o3
CROSS JOIN sys.all_objects o4
You should see 1 CPU pegged and 10MB/sec of disk writes. This shows how expensive row serialization is. We use about 10% of a magnetic disk only. This would use 10/225 of a P2’s write speed.
So it is dangerous to measure disk by using many rows.
This however gives 150MB/sec (on SSD) with half a CPU core used:
USE tempdb
CREATE TABLE T2 (ID INT NOT NULL PRIMARY KEY IDENTITY, Padding CHAR(7000))
INSERT INTO T2 (Padding)
SELECT ”
FROM sys.all_objects o1
CROSS JOIN sys.all_objects o2
CROSS JOIN sys.all_objects o3
CROSS JOIN sys.all_objects o4
=> A CPU-per-MB ratio of 30x! (At about 400x less rows per page.)
Thanks for the thoughts and comments. Your example of CPU-bound vs. I/O bound makes sense. I (almost!) entirely agree with you in terms of testing resources in isolation, though I have an additional question (in a moment!). As you say, the CPU and memory tests do test those resources almost entirely in isolation. I tried to do the same with the I/O tests to, up to a point. As you say, there is some CPU workload involved in row processing. Its effect is somewhere between the extremes of your two examples. So, yes, CPU will have some impact on these I/O results. I capture all data from the sys.dm_db_resource_stats DMV for the read and write tests. For the write-tests, I think the I/O impact is small, because the DMV shows these tests push that write resource at 98%, 99%, 100% throughout. For the read-tests, perhaps the impact is a little more. CPU utilisation tends to be 5% or less throughout the Standard tier read tests (so likely little impact). For the Premium tier read tests it is around 20% throughout, so it will have more of an impact, but it is by no means the dominant effect.
As I said I agree with your approach of testing resources in isolation, but, when it comes to I/O, I am not sure how the results of a test with 1-row-per-page would be easily scaled to say a test of rows of length 400 bytes. Is there a method you can use? SQL Server spends most of it’s time dealing with rows, so I used a row based test. Of course, that doesn’t mean the results of the test I used could be easily scaled either.
Databases are clearly complex beings and behave differently in different situations (hence the publicly defined OLTP benchmarks test a variety of scenarios). The test I have used is somewhere in between a pure I/O based test and a fuller range of OLTP benchmarks.
So, I do agree with you that I may not be finding the true I/O limits of the underlying performance tiers. My test results are only valid specifically for my test cases. Ultimately it would be interesting to run a much wider range of benchmarks but this would really need to be a community effort I think – too much time (and cost!) required for any individual to manage alone.
Or alternatively Microsoft could publish some additional information!
Thanks again for the thoughts and comments.
> Is there a method you can use?
I’d measure the requirements in terms of CPU, memory and disk on my local machine. Then I can immediately see what cloud machine I need to satisfy the requirements. No need to perform calculations.
Excellent work Chris. This makes for fascinating reading. I was about to embark on a similar exercise.
Chris, Excellent work. As a dedicated Azure user your information is excellent news for me. If it could be turned into a Benchmark it could be cloud changing! ok not for many things but maybe for SQL servers, it would be very interesting to see how a VM in Azure compares and also how competing cloud providers compare on a cost per Read Mbyte/second.
As a long time developer on Sql Server I feel that the Azure SQL has missed the point, it is no good having replicated databases, 99.9% SLA’s etc if the performance is as slow as Azure. (yes I do still love Azure). Anyone who has run an inhouse SQL HA cluster knows just how poor performing the Azure SQL Database is.
As an ex Data Centre provider Sql Server was the hardest server to provision and price, one malformed query, one out of date stat, or a front end app change could all result in huge cost increases on large production DB’s, while trying to get customers to action changes to systems when they didn’t have a financial reason to do so was impossible.
I do understand Microsoft’s decisions to rate and limit resources, it very hard for them. However a set of Benchmarks we could all use to compare would help stop the following that I have been party to; Not upgrading hardware for 5 years (no moores law here!), Being sure that this is as good as a customer can get (head in the sand!), Downstream infrastructure changes slowing real world performance (It must be faster now!).
p.s. Any chance of a delete performance test, having just discovered how bad it is.
p.p.s I now spend a lot of my time working out how Tables, Queues and Caching in Azure can reduce the need for SQL server, once the “Always on” is removed then SQL VM’s start to work nicely. The time cost to make solution changes is far more than running a proper SQL Cluster.
Simon
Hi
Thank you for the details. It is very good to see others test results – almost the same as ours.
we have created some DB’s – and found out the huge jump between V12-P1 and Regular P1.
The S3 – is also nice but even performance is bad then i thought. the problem in P1 is the Price 465*12=5580$ Per Year for only 500 GB – it is a lot…
So yes P1 is very good, i hope to see those performance in S3 too 🙂
Chris, this is excellent work and the entire Azure community is indebted to you.
I find it ridiculous that we have to resort to “concerned citizen” efforts like yours just to get some kind of indication on the resource allocations and performance of these new tiers.
What’s also concerning is that your benchmarks clearly show a change in real performance despite the DTU values of these tiers remaining completely unchanged.
Seriously WTF is the point of DTUs if the real performance underneath is a moving target?
DTUs are a typical Microsoft concept – great in theory, retarded and pointless in practice.
I have been in touch on and off with a couple of MS people regarding the new tiers and the lack of official benchmark information like yours.
Their response is that “every workload varies, so we’re not going to provide benchmarks or other details on resource allocation – DTUs are enough”.
According to them, every SQL Azure customer needs to simply migrate their database to the new tier and then just turn up the performance if needed. Never mind the huge jumps in fees each time we have to turn up the performance, and never mind the impact on our customers when the database is slow!
And never mind that most people familiar with databases like to optimise code for a given hardware/IO target rather than finding out on the fly and reacting in production!
Its all a bit of a mess and MS needs to take a hard look in the mirror on how they’ve handled all this.
The best thing we as a community can do is get Chris’s benchmarks up on Github for transparency’s sake, and refer everyone in the Azure world to this blog.
The sooner MS starts getting heat from all sides based on what these benchmarks say vs their DTU claims, the sooner they might actually get a clue and post some official, useful information on SQL Azure beyond DTUs.
A few words from our experience:
We have migrated to V12 (S3) from V11 Web/Business edition. 2 weeks ago. A few of our queries started to time out and we noticed an overall drop in performance of our SSRS reports (in some cases pretty significant).
It should be noted that we do not run overly complex queries nor deal with massive data size.
We will be testing P1 over the next 2 weeks but it will be very hard to justify its cost unless it offers significantly better performance…
One thought: If your data set is small (i.e. tending to rule out I/O and memory as the constrained resources), then it could be CPU related. My CPU tests showed that even S3 only has one-fifth of the CPU resources of my dev box (which is a 2.8 GHz Quad Core i7 from 2010). Did sys.dm_db_resource_stats provide any insight?
Also, do your reports perform any data writes? e.g. sprocs writing to tables / temp tables as the reports are run? If so, the lower write-rate in S3 compared to web/business could be the cause.
Any chance of adding P3?
Sorry, too expensive!
Great article, thank you. Did you also measure CPU improvements from V11 to V12? If I’m reading the table correctly it’s only for one version (V12, I suppose?)
I only ran the CPU tests against V12.
Thanks for this – it’s great information. I’m expecting to move to V12 next week and was hoping for some improvements in the power of the databases so your information has confirmed that will be the case.
The addition of the S3 in V12 was very important too as the gap between S2 and P1 is far too large on V11.
We’ve been running our database on a P1 Tier for several months now (migrated from Web/Business Edition). We’ve suffered from a lot of query time out issues upon roll out. This forced us to go back to the drawing board and optimize all the problematic queries, Not a bad thing obviously but since we run a pretty light database it was an unexpected effort.
We still suffer from rather poor performance today on the most complex queries that any optimization won’t be able to solve. Our study shows that the bottleneck today in P1 is the CPU allocation. We are hitting 100% CPU every day when these queries run (while other performance metrics remain low).
The only solution available to us is to move to SQL on a VM. Interestingly, a Basic instance give us much greater results than P1…. We are in close contact with the Microsoft team and hope the CPU allocation for P1 can be revised in a future update. But I would warn anyone against considering P1 databases for enterprise applications.
Hi Thierry… thanks for the follow up and comment (I know that you have followed Azure SQL DB on these posts since last year).
Your comments make sense. In my CPU tests at the start of the year (in this post), a P1 had one fifth of the CPU power of my Quad Core 2.8 GHz Intel i7, so less than one core of my CPU. That is not much for what is a relatively expensive performance tier. If anything CPU heavy is being performed in / offloaded to the database (e.g. large joins, XML processing, lots of ad-hoc queries, etc) then CPU is going to be even more of a problem.
Inline with the recent history of the cloud, storage is getting ever cheaper, but compute is really not.
Also, Azure SQL DB v12 Premium Tier has significantly higher I/O capabilities than v11 Premium Tier, so in some ways, it is not surprising that customers are seeing their workloads now becoming more CPU bound.
We also use a few databases with the Web tier and we’ll soon be forced to move to the new tiers (V12).
On the new portal they can recommend a new tier equivalent to the old one based on the usage.
I also verified this and what can I say.. thank you Microsoft. We’ll have to explain the customers somehow the increased cost.
You probably will end up paying more, but you won’t need to go from a Web to a P2 – Nice up-selling from them though :). Probably an S2 is your best starting point and monitor your usage to move it down or up.
In http://channel9.msdn.com/Shows/SQL-Unplugged/SQL-Unplugged-Live-Episode-4?wt.mc_id=EntriesInArea one of the experts literally said that P1 uses 1 CPU core, P2 = 2, P3 = 8.
According to your tests the true values are quite precisely 1/5 of that.
I don’t know what to make of these statements in light of your benchmark. An outright lie? Or are they thinking in terms of virtual cores that map to 1/5 of a core on the CPU that you tested?
Also I have the feeling that what Microsoft calls a “core” in IaaS VMs is less than a physical core. When I last looked at that it felt like 1/2 of a real core.
These factors make the cloud quite expensive from a $/throughput perspective.
My test machine was a quad-core (1 socket, four physical cores) 2.8GHz CPU. In my CPU tests, P1 was 0.2 of my whole CPU – i.e. P1 = 20% of the processing power supplied by all four of the cores in my CPU, so that makes P1 about 80% of one of the cores in my CPU. Following that logic, P1 equates to 1 core at 2.2GHz, which seems roughly in line perhaps with the figures you quoted from the channel 9 episode (I haven’t watched that).
I agree however, that obtaining a lot of CPU power in Azure SQL Database is not cheap!
So the query used for CPU tests was parallel? I did not notice that. If it was not parallel it could not have utilized your whole CPU.
Indeed, that brings in a factor of 4 (or with HT maybe 5). The statement by the Azure guy seems very credible now.
Does Azure support STATISTICS TIME? In that case it might be worthwhile to compare the CPU time consumed.
Re: anon above… yes, the query used was a parallel query and utilised the whole CPU.
Hi Chris, thank you, awesome work!
I may be able to help with some resources in order to teste the new P4 and maybe P6, interested?
Thanks for your comprehensive research in this area, we were having serious concerns around bulk insert performance on the new tiers not being anywhere near the previous business tiers without having to scale up and beyond a P2 and it was good to see your (earlier) post that verified this.
However, there seems to be a shift with v12 since we did the testing back in March 2015, we’re now seeing the same if not better performance with a P1 for bulk upload, whilst day-to-day transactional work is easily handled with an S2. Having scheduled vertical scaling jobs ensures that this remains a cost effective solution for us, particularly as our database sizes grow.
I also think that that the MS tier recommendations far exceeded our requirements, I think the problem comes from having weekend OLAP processing work that often hits 100% DTU (which we’re fine with), whilst the rest of the week its OLTP traffic with low DTU usage, MS clearly takes a simplistic view that your server is struggling so buy a better a tier.
Hi Chris,
This is a really good and interesting article, thanks, it includes a lot of useful information explained clearly. I benchmark tested a SQL Azure database recently and found performance slow and erratic in comparison with on premise virtual and physical SQL instances.
https://paulbrewer.wordpress.com/2015/12/03/sql_heartbeat-technical-summary/
Best wishes
Paul
Hi Paul,
One of the flaws (in my view) of Azure’s model is that the databases are throttled to allow Microsoft to apply a tiered pricing plan. The default database is an S0, which is so heavily throttled in so many ways that it’s near useless. I find that an S2 is the minimum requirement for a database which gets hit regularly.
You do see significant changes as you move up the Azure pricing models.
It might be worth you running your tests on an S2 or S3 and see how that affects your results.
Hi Gaz,
Thanks for the prompt, I didn’t realise we could scale our MSDN SQL Azure settings and try the other Performance Levels. The differences at the higher levels (S2 & S3) is really significant, as you suggested it would be.
Best wishes
Paul
Pingback: SQL Azure Performance Benchmarking | PaulBrewer@Yahoo.co.uk
Pingback: Azure SQL Database Pricing – Curated SQL
Pingback: Insert data in SQL Server at high speed (Part 1) – MenzoS Data Blog
Pingback: Comparing Cloud providers for new product development | 神刀安全网
Hi 🙂
A very good and thorough article. I have conducted similar observations in December 2016 and there is still much that can be improved in SQL Azure before one can call it a mature stable platform.
Feel free to look at the article I’ve written.
Click to access Azure%20%20performance%20report%201-2017-EN1.pdf
Regards
Marek
Pingback: SQL Server Performance Benchmarking with Patterns – Paul Brewer